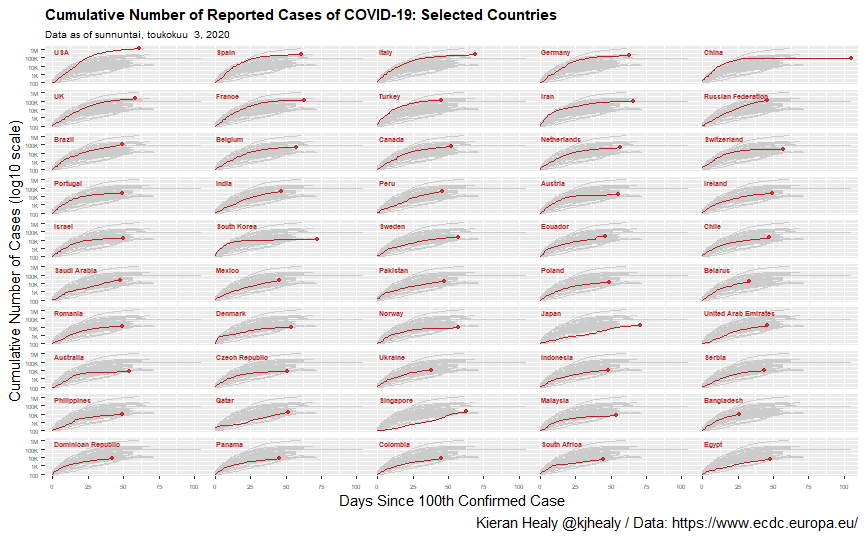
THL:n avoimen rajapinnan kautta pääsee lataamaan tartuntatautirekisterin tietoja suoraan alla olevan ohjeen mukaisesti. Alla listattuna tarvittavat R-kirjastot ja omina lisäyksinäni SQL -lauseet haluttujen tietojen poimintaan. Kevään mittaan olen näistä tehnyt päivittäin koosteita mm. Twitteriin ja toistaiseksi toiminut moitteettomasti. Eläköön avoinrajapinta. R-ohjelman voit ladata R-studio versiona täältä tai sitten voit käyttää vaihtoehtoisesti tätä versiota.
Have fun with R!
Marko
#Koodausohje-esimerkki R-kielellä
#Tässä esimerkissä haetaan THL:n rajapinnasta COVID-19-tapaukset ikäryhmittäin ja tehdään niistä aineisto.
#Paketti datan editoimiseen ja visualisointiin
library(tidyverse)
#Paketti datan lukemiseen
library(jsonlite)
library(sqldf)
library(DBI)
library(data.table)
HUOM VAIHDA AINA ENSIN PÄIVÄMÄÄRÄ
#190620
#100620
#-----------------------------------------
#IKÄRYHMITTÄIN
#----------------------------------------
#Paketti datan editoimiseen ja visualisointiin
library(tidyverse)
#Paketti datan lukemiseen
library(jsonlite)
library(sqldf)
library(DBI)
library(readr) # Read tabular data.
library(tidyr) # Data frame tidying functions.
library(dplyr) # General data frame manipulation.
library(ggplot2) # Flexible plotting.
mydb <- dbConnect(RSQLite::SQLite(), "my-db.sqlite")
#dbDisconnect(mydb)
#unlink("my-db.sqlite")
#otetaan edellispäivän data talteen
#Luetaan aineisto sisään
aineisto <- fromJSON("https://sampo.thl.fi/pivot/prod/fi/epirapo/covid19case/fact_epirapo_covid19case.json?column=ttr10yage-444309")
#puretaan kategoriat paloiksi
label <- as.data.frame(unlist(aineisto$dataset$dimension$ttr10yage$category$label))
index <- as.data.frame(unlist(aineisto$dataset$dimension$ttr10yage$category$index))
#Nimetään palaset
names(label)<-"label"
names(index)<-"index"
#Laitetana vielä rivinumerot sarakkeiksi, jotta nämä saadaan yhteen.
label<-rownames_to_column(label)
index<-rownames_to_column(index)
#Yhdistetään rivinimeä käyttäen
kategoriat <- index %>% left_join(label,by="rowname")
#otetaan data
data <- as.data.frame(unlist(aineisto$dataset$value))
data_old <- as.data.frame(unlist(aineisto$dataset$value))
#Nimetään
names(data)<-"Tapauksia"
names(data_old)<-"Tapauksia_edellispvm"
data<-rownames_to_column(data)
data_old<-rownames_to_column(data_old)
data$rowname<-as.numeric(data$rowname)
data_old$rowname<-as.numeric(data_old$rowname)
#Yhdistetään muuhun aineistoon
dataset_ir_190620 <- kategoriat %>% left_join(data,by=c("index"="rowname"))
dataset_ir_old <- kategoriat %>% left_join(data_old,by=c("index"="rowname"))
dataset_ir_190620
#VIEDÄÄN TULOKSET KANSIOON
write.table(dataset_ir_190620, file = "C:/...LISÄÄ TÄHÄN OMA POLKUSI/dataset_ir_190620.txt", sep = "\t", col.names = NA, qmethod = "double")
#katsotaan lopuksi tulokset
View(dataset_ir_190620)
#tässä kohtaa voi olla tarvetta hakea aikaisempia tietoja ja se tehdään seuraavalla tavalla
#LUETAAN KOONTI TAKAISIN
dataset_ir_200520 <- read.delim("C:/Users/marko/Dropbox/kuvat/home/Marko/R/koronadataa/dataset_ir_200520.txt")
View(dataset_ir_200520)
#vaihda päivämäärä, jotta saat halutun päivän tiedot tähän vertailuun mukaan
#tämä mikäli, et ole sitä jo tehnyt....
mydb <- dbConnect(RSQLite::SQLite(), "my-db.sqlite")
#ladataan taulut
dbWriteTable(mydb, "dataset_ir_140520", dataset_ir_140520)
#TÄMÄ JA EDELLINEN PÄIVÄ (muuta pvm tekstit oman tarpeesi mukaan)
rsa <- dbSendQuery(mydb, 'SELECT a.label, a.Tapauksia as Tapaukset_190620, b.Tapauksia as Tapaukset_180620, (a.Tapauksia)-(b.Tapauksia) as Muutos_lkm
FROM dataset_ir_190620 a
LEFT JOIN dataset_ir_180620 b
ON a.label = b.label')
dbFetch(rsa)
#tai sitten vaikka näin
#RAJOITUSTEN PURUSTA TÄHÄN PÄIVÄÄN
rsa <- dbSendQuery(mydb, 'SELECT a.label, a.Tapauksia as Tapaukset_190620, b.Tapauksia as Tapaukset_310520, (a.Tapauksia)-(b.Tapauksia) as Muutos_lkm
FROM dataset_ir_190620 a
LEFT JOIN dataset_ir_310520 b
ON a.label = b.label')
dbFetch(rsa)
Alla esimerkki, miten tiedot haetaan sukupuolittain.
#-----------------------------------------
#SUKUPUOLITTAIN
#----------------------------------------
#Paketti datan editoimiseen ja visualisointiin
library(tidyverse)
#Paketti datan lukemiseen
library(jsonlite)
library(sqldf)
library(DBI)
mydb <- dbConnect(RSQLite::SQLite(), "my-db.sqlite")
#dbDisconnect(mydb)
#unlink("my-db.sqlite")
#Luetaan aineisto sisään
aineisto <- fromJSON("https://sampo.thl.fi/pivot/prod/fi/epirapo/covid19case/fact_epirapo_covid19case.json?column=sex-444328")
#puretaan kategoriat paloiksi
label <- as.data.frame(unlist(aineisto$dataset$dimension$sex$category$label))
index <- as.data.frame(unlist(aineisto$dataset$dimension$sex$category$index))
#Nimetään palaset
names(label)<-"label"
names(index)<-"index"
#Laitetana vielä rivinumerot sarakkeiksi, jotta nämä saadaan yhteen.
label<-rownames_to_column(label)
index<-rownames_to_column(index)
#Yhdistetään rivinimeä käyttäen
kategoriat <- index %>% left_join(label,by="rowname")
#otetaan data
data <- as.data.frame(unlist(aineisto$dataset$value))
#Nimetään
names(data)<-"Tapauksia"
data<-rownames_to_column(data)
data$rowname<-as.numeric(data$rowname)
#Yhdistetään muuhun aineistoon
dataset_sp_190620 <- kategoriat %>% left_join(data,by=c("index"="rowname"))
dataset_sp_190620
write.table(dataset_sp_190620, file = "C:/....TÄHÄN OMA TIEDOSTOSIJAINTISI TULOSTIEDOSTOILLE.../dataset_sp_190620_sukupuolittain.txt", sep = "\t", col.names = NA, qmethod = "double")
#LUETAAN KOONTI TAKAISIN (MIKÄLI TARVETTA...) HUOM. TÄMÄ ON VAIN MALLI...
dataset_sp_190620 <- read.delim("C:/..TÄHÄN OMA TIEDOSTOSIJAINTISI.../dataset_sp_190620_sukupuolittain.txt")
View(dataset_sp_190620)
#ladataan taulut
dbWriteTable(mydb, "dataset_sp_190620", dataset_sp_190620)
#TOIMII
rsa <- dbSendQuery(mydb, 'SELECT a.label, a.Tapauksia as Tapaukset_190620, b.Tapauksia as Tapaukset_180620, (a.Tapauksia)-(b.Tapauksia) as Ero_eiliseen
FROM dataset_sp_190620 a
LEFT JOIN dataset_sp_180620 b
ON a.label = b.label')
dbFetch(rsa)
Seuraavaksi katsotaan, miten saadaan ladattua tiedot sairaanhoitopiireittäin.
#-----------------------------------------
#SAIRAANHOITOPIIREITTÄIN
#----------------------------------------
#Paketti datan editoimiseen ja visualisointiin
library(tidyverse)
#Paketti datan lukemiseen
library(jsonlite)
library(sqldf)
library(DBI)
mydb <- dbConnect(RSQLite::SQLite(), "my-db.sqlite")
#Luetaan aineisto sisään
aineisto <- fromJSON("https://sampo.thl.fi/pivot/prod/fi/epirapo/covid19case/fact_epirapo_covid19case.json?column=hcdmunicipality2020-445222")
#puretaan kategoriat paloiksi
label <- as.data.frame(unlist(aineisto$dataset$dimension$hcdmunicipality$category$label))
index <- as.data.frame(unlist(aineisto$dataset$dimension$hcdmunicipality$category$index))
#Nimetään palaset
names(label)<-"label"
names(index)<-"index"
#Laitetana vielä rivinumerot sarakkeiksi, jotta nämä saadaan yhteen.
label<-rownames_to_column(label)
index<-rownames_to_column(index)
#Yhdistetään rivinimeä käyttäen
kategoriat <- index %>% left_join(label,by="rowname")
#otetaan data
data <- as.data.frame(unlist(aineisto$dataset$value))
#Nimetään
names(data)<-"Tapauksia"
names(data_old)<-"Tapauksia_edellispvm"
data<-rownames_to_column(data)
data_old<-rownames_to_column(data_old)
data$rowname<-as.numeric(data$rowname)
data_old$rowname<-as.numeric(data_old$rowname)
#Yhdistetään muuhun aineistoon
dataset_shp_190620 <- kategoriat %>% left_join(data,by=c("index"="rowname"))
#dataset <- kategoriat %>% left_join(data,by=c("index"="rowname"))
dataset_shp_190620
#plot(dataset_shp_190620)
write.table(dataset_shp_190620, file = "C:/...TÄHÄN OMA TIEDOSTOSIJAINTISI.../dataset_shp_190620_shp.txt", sep = "\t", col.names = NA, qmethod = "double")
#ja jos on tarvetta niin ladataan vanhaa dataa näin...
#LUETAAN KOONTI TAKAISIN
dataset_shp_050520 <- read.delim("C:/...TÄHÄN OMA TIEDOSTOSIJAINTISI.../dataset_shp_050520_shp.txt")
View(dataset_shp_050520)
#ladataan taulut (jos tarvetta...)
#dbWriteTable(mydb, "dataset_shp_050520", dataset_shp_050520)
#tämä täytyy kyllä tehdä, jotta alla oleva kysely saadaan toimimaan...
dbWriteTable(mydb, "dataset_shp_190620", dataset_shp_190620)
#EILISEEN VERRATTUNA
rsa <- dbSendQuery(mydb, 'SELECT a.label, a.Tapauksia as Tartunnat_190620, b.Tapauksia as Tartunnat_180620, (a.Tapauksia)-(b.Tapauksia) as Ero_edellispäivään
FROM dataset_shp_190620 a
LEFT JOIN dataset_shp_180620 b
ON a.label = b.label')
dbFetch(rsa)
#RAJOITUSTEN HÖLLENTÄMINEN 1.6. LÄHTIEN
rsa <- dbSendQuery(mydb, 'SELECT a.label, a.Tapauksia as Tartunnat_190620, b.Tapauksia as Tartunnat_310520, (a.Tapauksia)-(b.Tapauksia) as Muutos_31_5_lähtien
FROM dataset_shp_190620 a
LEFT JOIN dataset_shp_310520 b
ON a.label = b.label')
dbFetch(rsa)
#RAJOITUSTEN POISTO - KOULUJEN AVAUS
rsa <- dbSendQuery(mydb, 'SELECT a.label, a.Tapauksia as Tartunnat_190620, b.Tapauksia as Tartunnat_130520, (a.Tapauksia)-(b.Tapauksia) as Muutos_13_5_lähtien
FROM dataset_shp_190620 a
LEFT JOIN dataset_shp_130520 b
ON a.label = b.label')
dbFetch(rsa)
Kuntakohtaiseen dataan pääsee käsiksi alla olevan koodin kautta….
#-----------------------------------------
#KUNNITTAIN
#----------------------------------------
#Paketti datan editoimiseen ja visualisointiin
library(tidyverse)
#Paketti datan lukemiseen
library(jsonlite)
library(sqldf)
library(DBI)
#Luetaan aineisto sisään
aineisto <- fromJSON("https://sampo.thl.fi/pivot/prod/fi/epirapo/covid19case/fact_epirapo_covid19case.json?column=hcdmunicipality2020-445268L")
#puretaan kategoriat paloiksi
label <- as.data.frame(unlist(aineisto$dataset$dimension$hcdmunicipality$category$label))
index <- as.data.frame(unlist(aineisto$dataset$dimension$hcdmunicipality$category$index))
#Nimetään palaset
names(label)<-"label"
names(index)<-"index"
#Laitetana vielä rivinumerot sarakkeiksi, jotta nämä saadaan yhteen.
label<-rownames_to_column(label)
index<-rownames_to_column(index)
#Yhdistetään rivinimeä käyttäen
kategoriat <- index %>% left_join(label,by="rowname")
#otetaan data
data <- as.data.frame(unlist(aineisto$dataset$value))
#Nimetään
names(data)<-"Tapauksia"
data<-rownames_to_column(data)
data$rowname<-as.numeric(data$rowname)
#Yhdistetään muuhun aineistoon
dataset_kunta_190620 <- kategoriat %>% left_join(data,by=c("index"="rowname"))
#TALLENNETAAN OMAAN TIEDOSTOSIJAINTIIN MYÖHEMPÄÄ KÄYTTÖÄ VARTEN...
write.table(dataset_kunta_190620, file = "C:/...TÄHÄN OMA TIEDOSTOSIJAINTI.../dataset_kunta_190620_kunnittain.txt", sep = "\t", col.names = NA, qmethod = "double")
#KATSOTAAN VIELÄ MILTÄ POIMINTA NÄYTTÄÄ...
dataset_kunta_190620
#LUETAAN KOONTI TAKAISIN, MIKÄLI TARVITSET VANHOJA FILUJA....
dataset_kunta_040520 <- read.delim("C:/...TÄHÄN OMA.../dataset_kunta_040520_kunnittain.txt")
View(dataset_kunta_040520)
#ladataan taulut
#dbWriteTable(mydb, "dataset_kunta_040520", dataset_kunta_040520)
#dbWriteTable(mydb, "dataset_kunta_050520", dataset_kunta_050520)
#dbWriteTable(mydb, "dataset_kunta_060520", dataset_kunta_060520)
#dbWriteTable(mydb, "dataset_kunta_070520", dataset_kunta_070520)
#dbWriteTable(mydb, "dataset_kunta_080520", dataset_kunta_080520)
#dbWriteTable(mydb, "dataset_kunta_090520", dataset_kunta_090520)
#dbWriteTable(mydb, "dataset_kunta_100620", dataset_kunta_100620)
#dbWriteTable(mydb, "dataset_kunta_130520", dataset_kunta_130520)
#dbWriteTable(mydb, "dataset_kunta_010620", dataset_kunta_010620)
dbWriteTable(mydb, "dataset_kunta_190620", dataset_kunta_190620)
#LUODAAN NÄKYMÄ (VIEW) JA TEHDÄÄN VERTAILU EDELLISPÄIVÄÄN
dbExecute(mydb, 'CREATE VIEW dataset_sortattu_kunta_190620a AS SELECT a.label, a.Tapauksia as Tartunnat_190620, b.Tapauksia as Tartunnat_180620, (a.Tapauksia)-(b.Tapauksia) as Lisäys
FROM dataset_kunta_190620 a
LEFT JOIN dataset_kunta_180620 b
ON a.label = b.label ORDER BY Lisäys DESC')
#View(dataset_sortattu_kunta_190620)
#TOIMII MUTTA ANTAA SAMAN SARAKDATAN KUIN TÄMÄN PÄIVÄN TUTKI TUTKI
rsa <- dbSendQuery(mydb, 'SELECT * FROM dataset_sortattu_kunta_190620a ORDER BY Lisäys DESC')
dbFetch(rsa)
Ladataan vielä päiväkohtainen data ie. tartunnat päivittäin.
#“An inefficient virus kills its host. A clever virus stays with it.”
#—James Lovelock
#-----------------------------------------
#PÄIVITTÄIN
#----------------------------------------
#Paketti datan editoimiseen ja visualisointiin
library(tidyverse)
#Paketti datan lukemiseen
library(jsonlite)
library(sqldf)
library(DBI)
#Luetaan aineisto sisään
aineisto <- fromJSON("https://sampo.thl.fi/pivot/prod/fi/epirapo/covid19case/fact_epirapo_covid19case.json?column=dateweek2020010120201231-443702L")
#puretaan kategoriat paloiksi
label <- as.data.frame(unlist(aineisto$dataset$dimension$dateweek$category$label))
index <- as.data.frame(unlist(aineisto$dataset$dimension$dateweek$category$index))
#Nimetään palaset
names(label)<-"label"
names(index)<-"index"
#Laitetana vielä rivinumerot sarakkeiksi, jotta nämä saadaan yhteen.
label<-rownames_to_column(label)
index<-rownames_to_column(index)
#Yhdistetään rivinimeä käyttäen
kategoriat <- index %>% left_join(label,by="rowname")
#otetaan data
data <- as.data.frame(unlist(aineisto$dataset$value))
#Nimetään
names(data)<-"Tapauksia"
data<-rownames_to_column(data)
data$rowname<-as.numeric(data$rowname)
#Yhdistetään muuhun aineistoon
dataset_day_190620 <- kategoriat %>% left_join(data,by=c("index"="rowname"))
dataset_day_190620
#TALLENNETAAN TIEDOT KANSIOON...
write.table(dataset_day_190620, file = "C:/..TÄHÄN OMA TIEDOSTOSIJAINTISI.../dataset_day_190620_paivittain.txt", sep = "\t", col.names = NA, qmethod = "double")